
This is a demonstration of how to get started with DeFi on Partisia Blockchain focusing on interacting with smart contracts directly via blockchain explorer on TestNet and building DEXes based on the Scalable AMM framework developed by co-founder, Kurt Nielsen. There’s currently teams building out DeFi on Partisia Blockchain for MainNet – one example is zkCross Network.
This new AMM DEX design is intended for builders to reinvent traditional finance with a more fair and compliant DEX that ensures scalability, price guarantee, and frontrun protection – all features you will not find in a regular DEX model out-of-the-box. Note that this guide is a walkthrough of a low-level interface to learn the mechanics, and we are encouraging teams to take this and build a user-friendly DeFi app on top of these contracts. Is your team ready to build the next frontier of finance? Read more about our Grants Program.
First things first, let’s meet the testnet tokens and smart contract that we will be using in this guide.
Now, go to Partisia Blockchain’s Discord server and open a #support-ticket. Choose Developer Support option, and indicate you need test gas and IWH tokens. If you don’t have a wallet already, you can use Parti Wallet. Note: to show your MPC20 tokens in Parti Wallet, go to the “MPC20” tab and then “Manage Tokens”.
Here we use the DEX router for swapping across multiple pairs and liquidity pools to demonstrate the lock-swap price guarantee concept that can be used for building scalable DeFi that operates cross-chain and on multiple shards. In this case we will swap IWH to PPE.
1. Go IvanWifHat (IWH) token contract and sign in with your wallet.
2. Select “Approve” under the “INTERACT” dropdown.
3. Insert the smart contract address of DEX router in “Spender”, select the amount you want to swap (e.g. 50000), and hit “APPROVE” to sign the transaction via your wallet.
Remember IWH has 4 decimals e.g. if you want to approve 5 IWH, insert 50000 in “Amount”. In this guide we use 50000 in “Amount”.
Approval is needed before the DEX router can manage your tokens for the swap.
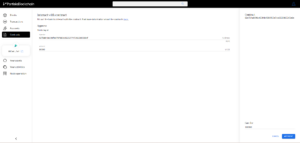
4. Now go to DEX router and select “Route swap” from the “INTERACT” dropdown.
5. Insert the smart contract address from IvanWifHat (IWH) in the “Token in” field and the smart contract address of PeterPepe (PPE) in “Token out”. Insert the amount you want to swap in “Amount in” e.g. 50000, and the minimum amount you are willing to receive from the swap in “Amount out minimum” e.g. 40000. Click “ADD ADDRESS” twice under “Swap route” and insert the smart contract addresses of QTK/IWH liquidity pool and PPE/QTK liquidity pool in respective order. This will define the route of your swap through liquidity pools. Adjust the gas fee to 500000 and hit “ROUTE SWAP”.
When you set the “Amount out minimum”, take into consideration that each liquidity pool takes a 3% swap fee, gas fees and slippage. In this example we use 50000 “Amount in” and 40000 “Amount out minimum”.
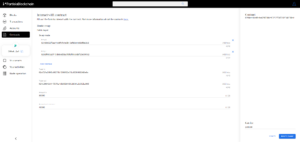
6. Examine the transaction hash to explore routing and the lock-swap price guarantee concept, and check the assets in your wallet.
Now, if you hold two tokens that correspond to a pair in a liquidity pool, you can become a liquidity provider (LP) to earn revenue from the fees paid by other users that swap.
First, make sure you have swapped your way to hold either QTK and IWH or PPE and QTK. In the below example we use QTK/IWH. See above section “Swap via router” for instructions.
1. Go to IvanWifHat (IWH) and approve the smart contract address of QTK/IWH liquidity pool to spend the amount of that token you want to supply as liquidity. Do the same for QuantumKurt (QTK).
Again, remember that IWH, QTK and PPE has 4 decimals.
2. Then go to QTK/IWH liquidity pool and select “Deposit” under “INTERACT”. Now insert the smart contract address of IvanWifHat (IWH), specify the amount, and hit “DEPOSIT”. Do the same for QuantumKurt (QTK).

3. Next, go to the QTK/IWH liquidity pool and select “Provide liquidity” under “INTERACT”. Then insert the smart contract address of IvanWifHat (IWH), specify the amount, and hit “PROVIDE LIQUIDITY”. Do the same for QuantumKurt (QTK).
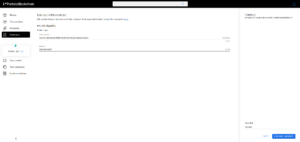
4. Go QTK/IWH liquidity pool and examine the smart contract state to see your LP.
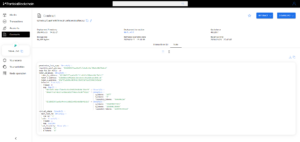
5. If you want to reclaim your liquidity and transfer the tokens back to your account, then use the “Reclaim liquidity” and “Withdraw” function.
You can find all DeFi smart contract templates here if you are interested in deploying your own DEX and explore all functionalities as operator. For more information on how to compile, deploy and interact with smart contracts, please visit the smart contract documentation. Connect with us on Discord for our tech Q&A and apply for our Grants Program if you are interested in building DeFi on mainnet.
Stay updated: Website • X • Discord • Telegram • LinkedIn • Facebook • Instagram • GitLab • Medium • YouTube
As explained in our BYOC documentation, Partisia Blockchain (PBC) has a multi-chain solution where gas for transaction in PBC is paid using external coins. To help developers add additional tokens into the chain, we have a framework that allows anyone who meets the requirements to add other tokens as a bridgeable asset and include them into the payment system. This document’s aim is to provide instructions on how you can add other tokens into the Partisia Blockchain ecosystem.
Currently the framework supports any tokens that run under Ethereum, Polygon or BNB chain. As other L1 chains get added, other tokens will become available under the BYOC Framework.
In the coming weeks we will provide additional guides and videos to walk you through the process, for both the node operators and the proposer. We hope this article will help you begin to consider what tokens you would like to onboard as payment.
We are proud to introduce to the community one of our major roadmap items, the BYOC framework.
Interoperability and decentralization is one of our core values of our blockchain and one of our goals is to enable anyone to harness the capabilities of MPC. This is why our BYOC architecture was created in the first place, allowing the onboarding of any liquid assets to be usable as transaction fees (gas) on our blockchain.
Until now the foundation has proposed and enabled the onboarding of ETH, Polygon USDC and BNB as forms of payment. But our long term goal always was to allow for the community to make decisions on what tokens should be enabled on our chain.
The BYOC framework will now allow for the community to propose any tokens running on the Ethereum, BNB or Polygon chains to be usable as gas payment. The proposal then will go to our validators who will then make the final vote on whether or not to onboard the token as form of payment on Partisia Blockchain.
In the coming days we will share additional details and instructions on how the community can create a proposal for a token to be enabled on Partisia Blockchain. The foundation will initially start by submitting proposals to enable both USDT and MATIC tokens, and create detailed instruction guides using these two tokens as templates to help guide the community to onboard other tokens of their choice.
We are very excited to introduce this new feature and looking forward to seeing other great tokens being introduced by the community into our bridge.
The point of this document is to provide the shortest (and most intuitive) possible introduction to each of the technologies mentioned in the title. I hope I succeed in this endeavor.
The technologies in this document all — with exception of differential privacy — deal with “secure” computation on data. At a very high level, this means they can be used to perform an arbitrary computation on one or more pieces of data, while keeping this data private.
Secure multiparty computation, which is what we do here at Partisia, is the term for a fairly broad class of protocols that enable two separate entities (called parties) to compute a function, while revealing nothing except the output.
An MPC protocol typically proceeds in three phases: First the inputters secret-share their private inputs. This step can be thought of as each user sending a special type of encryption of their inputs to the nodes doing the computation. The encryption ensures, for example, that at least two out of three nodes are required to recover the input, and thus, we get a security model that relies on non-collusion. It could also be the case that all three nodes must collude to recover the input — in this case, we have a full threshold model (since all servers must collude to break privacy).
The next step involves the nodes (the servers A, B, and C) performing the computation on the encryptions (i.e., secret-shares) received in the input step.
When the nodes finish the computation, they will hold a secret-sharing of the output. Each node’s share is returned to the users, so they can recover the actual output.
As might be inferred from the figures above, MPC works particularly well if the computation nodes are well-connected. Indeed, what makes MPC expensive to run is all the data that the nodes have to send between each other.
MPC have been actively studied in academia since the early 1980s and there are a lot of good resources available to learn more about it:
Fully homomorphic encryption (FHE) solves a very old problem: Can I have my data encrypted and compute on it too? FHE is a tool that allows us to not only store data encrypted on a server, but which allows the server to compute on it as well, without having to decrypt it at any point.
A user encrypts their private data and uploads it to a server. However, unlike a traditional E2EE (End-to-End-Encrypted) scenario, the server can actually perform a computation on the user’s private data — directly on ciphertext. The result can then be decrypted by the user using their private key.
FHE, unlike MPC, relies on clever cryptographic computation, rather than clever cryptographic protocols. On the one hand, this means FHE requires less data to be sent between the server and client compared to MPC. On the other hand, FHE requires a lot of computation to be done by the server.
Practically speaking, FHE is slower than MPC (unless we have an incredibly slow network, or incredibly powerful computers).
Practical FHE is a relatively new technology that only came about in 2009. However, since then it has received quite a bit of interest, especially from “bigger” players like Microsoft or IBM.
Partisia Blockchain supports FHE solutions.
While both MPC and FHE allow us to compute anything, zero-knowledge proof (ZKP) systems allow us to compute proofs. In short, ZKP allows us to compute functions where the output is either “true” or “false”.
ZKPs are incredibly popular in the blockchain space, mainly for their role in “rollups”. The particular type of ZKPs used for rollups are ZK-SNARKs, which are succinct proofs. In a nutshell, a succinct proof is a proof whose size is some fixed (small) constant, and where verification is fast. This makes smart particularly useful for blockchains since the proof and verification are both onchain.
That said, ZK rollups don’t actually use the zero-knowledge property — they only use the soundness and succinctness properties of the proof scheme.
Soundness simply means that it is very difficult to construct a proof that appears valid, but in actuality is not.
ZKPs, like FHE, takes place between a single user and a verifier. The user has a secret and they wish to convince the verifier about some fact concerning this secret, without revealing the secret. ZKPs don’t designate a particular verifier, so anyone can usually check that a proof is correct.
The final private computation technology I will talk about here is trusted execution environments. A trusted execution environment, or TEE, is basically just a piece of hardware that is trusted to do the right thing. If we trust this particular type of hardware, then private computing is clearly doable.
TEEs, being hardware, are tightly connected to some hardware vendor. Often when TEEs are mentioned, what is really meant is something like Intel’s SGX or ARM TrustZone. SGX is the TEE used by Secret Network, for example.
The security model of TEEs is fairly different compared to the other technologies I have written about so far, in that it is a lot more opaque. Vulnerabilities have been demonstrated in different iterations of different TEE products, especially SGX.
Differential privacy is radically different from the previous technologies. (In this discussion I will exclude ZKPs since it does not allow general computations.)
While MPC, TEE and FHE all provide means of computing something on private data, they do not really care about what that something is.
For example, it is possible (albeit pointless) to compute the identity function using both MPC, TEE and FHE.
This is because MPC, TEE and FHE allow us to compute anything. In particular, they allow us to perform computations that are not really private.
At this point, we may ask: Well, why would we perform such a silly computation on private data? For some computations, it might be easy to see that it is not private (in the sense that the original input can easily be inferred from the output). However, there are many computations that are seemingly private, but which can also leak the input if we are not careful. For example, it has been shown that it is possible to extract machine learning models, simply by querying a prediction API. In another example it was shown that it is possible to extract the data that a model was trained on.
These issues all arise because there are no restrictions on the computation that is performed. Differential privacy tries to fix this.
Differential privacy is used to provide a fairly intuitive guarantee. Suppose we are given two databases A and B. The only difference between these two databases, is that a particular entry R exists in A but not in B. Differential privacy now states that, no matter which type of query we make on the database, we will not be able to guess whether we are interacting with A or B.
Naturally, this means that some queries cannot be allowed. For example, it is not possible to obtain differential privacy if one can simply ask “Is record R in the database?”. Generally, differential privacy is obtained by adding noise, or synthetic data, to the database as well as restricting the type of queries that are allowed.
What makes differential privacy different from MPC, TEE and FHE, is that differential privacy makes guarantees about the output of a computation, whereas MPC, TEE and FHE makes guarantees about the process of arriving at that output. In summary:
This also means that differential privacy is not in direct “competition” with MPC, TEE or FHE, but rather complements them.
While each technology has its specific advantages and use cases, it is our feeling that Partisia Blockchain’s MPC, backed by 35 years of research and practical implementation does seem to provide the most overall coverage of all possible scenarios with very little drawback.
Website • Twitter • Discord • Telegram • LinkedIn • Facebook • Instagram • GitLab • Medium • YouTube
A blockchain, at its very core, is a way for everyone to agree on what the current state of the world is, without having to rely on a trusted authority.
Of course, by “everyone” we don’t actually mean everyone, but instead everyone who believes in the security model. Likewise, by “the world” we also don’t actually mean the world, but rather, whatever is currently written on the blockchain’s ledger. Nevertheless, well-known blockchains such as bitcoin or ethereum both have market caps in the 100s of billions of USD, which tells us that the technology excites people.
Programmable blockchains, in particular, are exciting because their “world” is very rich. On a programmable blockchain, the “world” is basically the current memory of a computer, and so, simply by being clever about how we design the programs that run on this computer, we can use it to accomplish almost anything.
Let’s digress for a bit and classify programs into three categories:
— Those that take a public input and produce a public output
— Those that take a private input and produce a public output
— Those that take a private input and produce a private output
A programmable blockchain such Ethereum supports programs of the first kind: Everyone sees what goes into a smart contract on Ethereum, and everyone sees what comes out again. This is great for some applications (like agreeing on who bought a NFT), but clearly not sufficient for others (like performing an auction).
Several solutions have surfaced which attempt to support the remaining two types of computations. Let’s take a brief look at some of them:
Zero-knowledge proofs (ZKPs) are, in a nutshell, a way for someone to convince (i.e., prove to) someone that they know or possess something, without revealing anything about that something. One situation where this shows up, is when someone wishes to prove to someone else that they control a certain amount of tokens.
ZKPs can therefore be used for private-public and private-private computation, to a limited degree. ZKPs can only compute, well, proofs. This in particular means that the computations are limited to a binary “yes” or “no” output. Moreover, ZKPs are inherently single-user oriented, so it is not possible to perform a computation that takes multiple private inputs.
Note that a program that takes a public input, but produces a private input does not make sense. If everyone can see the program and what goes into it, then everyone can obviously see the output as well.
Another private computation technique is fully homomorphic encryption, or FHE as it is called for short. At its very basic, FHE is a way of encrypting data such that it is possible to perform computations directly on the encryption.
This immediately tells us that FHE for sure supports private input private output type computations.
However, FHE, like ZKPs, are oriented towards a single user scenario. This means that, although FHE can perform any computation (which ZKPs cannot do), they cannot perform a computation that receives private inputs from multiple users.
In contrast to the two above technologies (as well as the next one), trusted execution environments (shortened as TEEs) are a purely hardware based solution to the private computing problem we’re looking at.
A TEE is simply a piece of hardware that have been hardened in certain ways that make it hard to break into. If we believe this to be the case, then a TEE can be used to perform the private input, public/private output computations we’re interested in.
Inputs are encrypted using a key stored only on the TEE, and computations take place on the TEE after decryption. When the computation is done, the output is encrypted (or not, depending on whether the output should be public or private) and then output by the TEE. In this way.
TEEs therefore clearly support the type of single-private-input computations talked about so far. However, the situation is a bit complicated if we want to receive inputs from multiple sources. Indeed, the only way that can be possible, is to make sure the same key is stored on everyone’s TEE.
The last tech I will look at is secure multiparty computation, or MPC. This privacy tech supports both types of computations, just like FHE and ZKPs, but where it distinguishes itself is that it naturally supports private inputs from multiple sources. Indeed, there’s a reason it’s called secure multiparty computation.
This makes MPC especially suited for a blockchain because of its multi-user nature.
The above categorization leaves out a lot of details, since it talked about neither the security models that each of the technologies use, nor about their efficiency.
Each of the four technologies above operate in a particular security model, and none of the models are exactly the same. Likewise, they each have some properties that make them desirable compared to the others. (For example, FHE requires more computation, but less communication, than MPC.)
In general, MPC does seem to come out on top, and is the only technology that easily supports computations where multiple users provide inputs. MPC, by its nature, is a decentralized technology, which is probably why it works so well in a blockchain setting. That being said, an ideal world would probably use all of the technologies in a carefully created orchestration to ensure the best guarantees in terms of both security and efficiency.
Website • Twitter • Discord • Telegram • LinkedIn • Facebook • Instagram • GitLab • Medium • YouTube